
Mutual Q-learning
Last night around midnight, I presented a bit of work on the topic of mutual reinforcement learning. We showed that if you allow a couple of AI agents to communicate their belief about a particular state, they can learn more quickly than they might otherwise, which is neat!
The idea behind mutual learning is that you have a few agents, and they’re trying to learn to solve the same problem. Mutual learning is the task of allowing them to work together to learn more quickly – think about kids in school working together on an assignment. They were all given the same lesson, but maybe they internalized different parts and when they come together and communicate, they can do better.
The first really promising results to come from this field were published in 2018, in a paper called Deep Mutual Learning. In that paper, they show that many neural networks can collaborate on the learning process and get better results than they get by themselves. In particular, they show that smaller neural networks can achieve performance on par with larger neural networks if they work together during learning.
How does that work? Well, normally, if you’re training a neural network to tell you if a picture includes a hot dog or not, you show it a bunch of pictures and you tell it “there’s a hot dog there” or “there’s no hot dog there”, and you push the parameters of the neural network in the direction that makes it output the correct answer as often as possible. The “collaboration” mentioned here happens by pushing the parameters of the neural network not only in the direction of “guess the hot dog”, but also “agree with your partner”.
In our present work, we explore the process of applying a similar technique to reinforcement learning. Reinforcement learning is a bit different, because you have no ground truth. Imagine a game of chess. In normal Q-learning, you want to answer the question, “How good is this move from the position I’m in?”, and you answer it by saying “That move is as good as the best move you can make from the position you end up in.” If that seems a bit circular, that’s because it is, which is why it’s no guarantee that the deep mutual learning approach will work here; all of your learning agents are just making guesses, and you’re forcing them into agreement with other guesses, but there’s no external validation there.
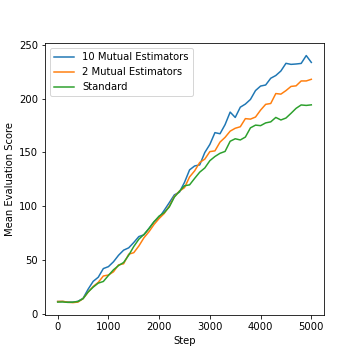
And it works! With 10 mutually-learning neural networks operating on the same environment, the agent performs about 27% better, on average, than a traditional Q-learning approach.
A lot of work (PDF) has been done asynchronous medeep reinforcement learning algorithms – methods that use a lot of instances of the same neural network to learn more quickly. I think the work we presented gives a promising area of exploration for improvement to those methods. I also think there are some exciting possibilities on the “multiagent systems” front.